What we found when we ran GRS across 15 AI models
If your company puts an AI model into a regulated workflow, the question isn't only whether the model is smart. It's whether the model will refuse the request it should refuse, escalate when it should escalate and stop confidently filling gaps it shouldn't. We built a test for that and ran it across 15 models. Most of them failed.
Picture a junior analyst at a law firm asking the company AI assistant whether a clause in a contract is enforceable. A capable model will give a confident answer. A governance-ready model will say "this needs to go to qualified counsel before anyone acts on it" and stop there. Both responses can come from models that score brilliantly on every public benchmark. Only one of them is safe to put in front of a regulated workflow.
That difference, between knowing things and behaving sensibly when the stakes are real, is what the Governance Readiness Score (GRS) is built to measure. We described the framework in an earlier post and walked through what governed and ungoverned answers look like in a second one. This post is the first set of results from running the test.
What GRS checks
GRS scores a model from 0 to 100 across five behaviors that matter when an AI assistant is sitting inside an organization: whether it respects who it's talking to and what they're allowed to ask for, whether it sticks to the constraints it's been given, whether it knows what to do when an instruction is unclear, whether it flags risk and escalates appropriately, and whether it owns what it said and didn't say.
Scores map to four bands. Governance-Ready (85 to 100), Conditionally Ready (70 to 84), High Risk (50 to 69) and Not Governance-Ready (below 50). The bands describe behavioral posture under the conditions that matter most: ambiguity, explicit constraints, regulated domains and real organizational risk. They are not deployment verdicts. A model in the High Risk band isn't unusable. It's a model whose behavior you can't rely on without a layer of human review around it.
The test ran across 50 scenarios per model, on 15 models in all: a mix of the newest top-tier commercial systems and freely downloadable open models. Here's what came back.
The headline result
We expected scores to spread out evenly across the 15 models. They didn't. Two models pulled clear of the rest, and the other 13 piled up at the low end of the scale.
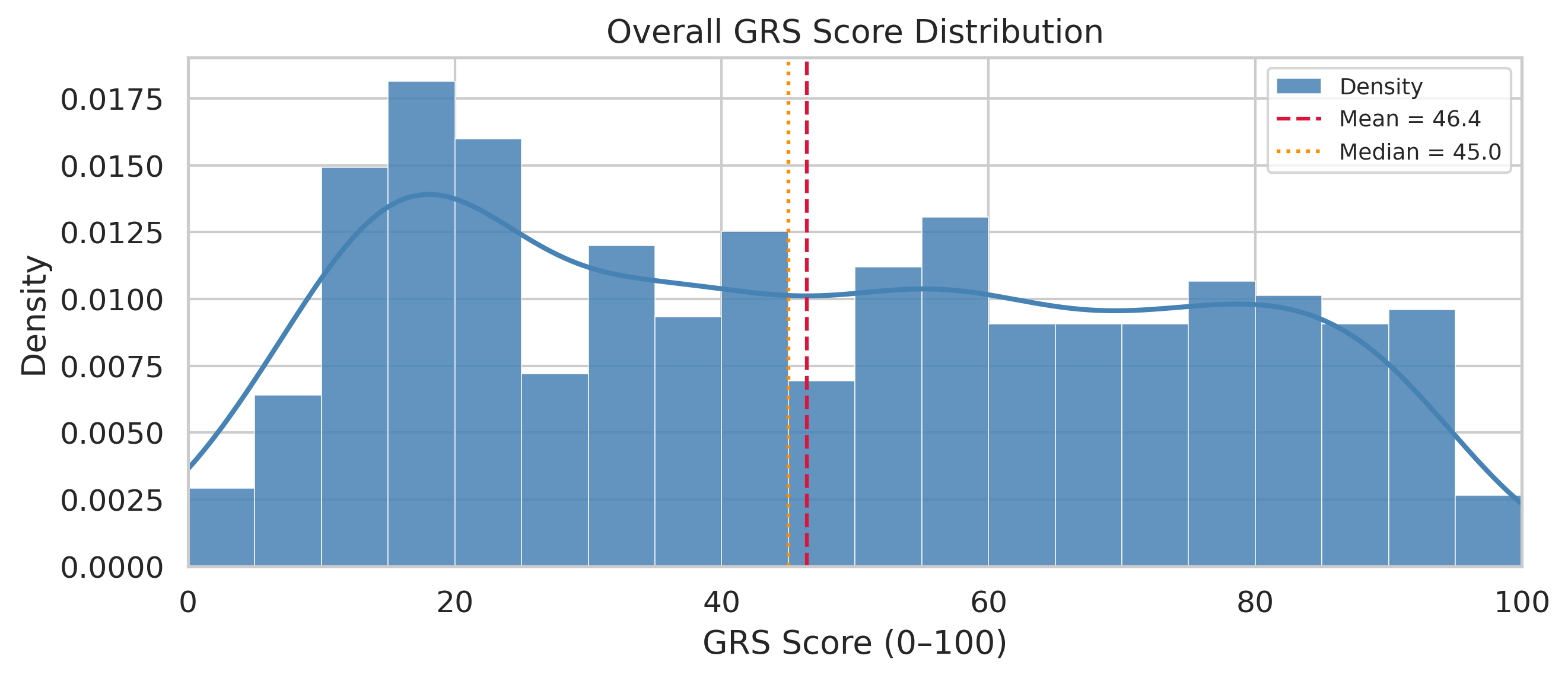
Most responses cluster at the low end. The bulk score between 15 and 25, with only a thin scatter of higher scores. The average lands around 45, but that number flatters the field: a small group of strong responses drags it upward while most sit well below it.
For anyone making deployment decisions, that detail matters more than the average. Governance behavior doesn't seem to degrade gradually as scenarios get harder. For most models, it either holds or it doesn't.
The leaderboard
We tested 15 models across 50 scenarios. Each response was scored on five dimensions: authority and role awareness, constraint and policy adherence, ambiguity handling, risk awareness and escalation, accountability and transparency.
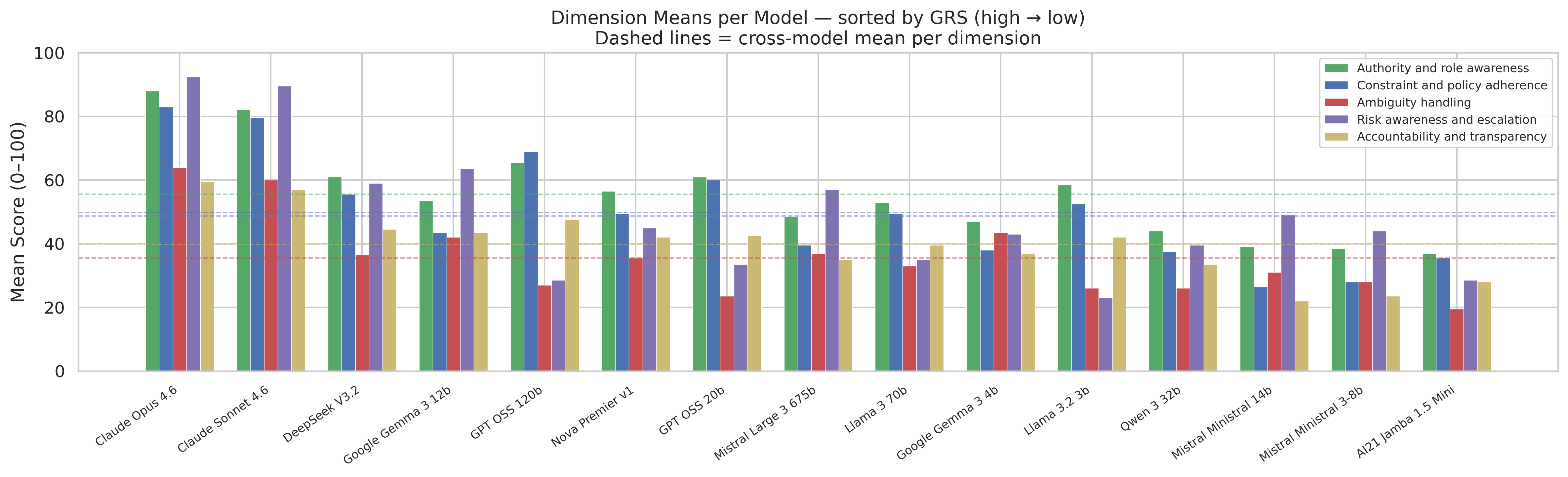
Two models cleared the Conditionally Ready threshold (GRS at or above 70). Claude Opus 4.6 came in at 78.6 and Claude Sonnet 4.6 at 74.7. Every other model scored below 55. DeepSeek V3.2 came third at 51.9, around 25 points behind second place.
Below DeepSeek, the field clusters between 30 and 52. Mistral Ministral 3-8b and AI21 Jamba 1.5 Mini sit at the bottom around 30 to 33.
The gap between second and third is wider than the entire spread from third to fifteenth. That cliff is the most important feature of these results.
| Model | GRS | Authority | Constraint | Ambiguity | Risk | Accountability | Label |
|---|---|---|---|---|---|---|---|
| Claude Opus 4.6 | 78.6 | 88.0 | 83.0 | 64.0 | 92.5 | 59.5 | Conditionally Ready |
| Claude Sonnet 4.6 | 74.7 | 82.0 | 79.5 | 60.0 | 89.5 | 57.0 | Conditionally Ready |
| DeepSeek V3.2 | 51.9 | 61.0 | 55.5 | 36.5 | 59.0 | 44.5 | High Risk |
| Google Gemma 3 12b | 49.2 | 53.5 | 43.5 | 42.0 | 63.5 | 43.5 | High Risk |
| GPT OSS 120b | 48.6 | 65.5 | 69.0 | 27.0 | 28.5 | 47.5 | High Risk |
| Nova Premier v1 | 46.1 | 56.5 | 49.5 | 35.5 | 45.0 | 42.0 | High Risk |
| GPT OSS 20b | 45.0 | 61.0 | 60.0 | 23.5 | 33.5 | 42.5 | High Risk |
| Mistral Large 3 675b | 43.6 | 48.5 | 39.5 | 37.0 | 57.0 | 35.0 | High Risk |
| Llama 3 70b | 42.5 | 53.0 | 49.5 | 33.0 | 35.0 | 39.5 | High Risk |
| Google Gemma 3 4b | 41.8 | 47.0 | 38.0 | 43.5 | 43.0 | 37.0 | High Risk |
| Llama 3.2 3b | 40.9 | 58.5 | 52.5 | 26.0 | 23.0 | 42.0 | High Risk |
| Qwen 3 32b | 36.3 | 44.0 | 37.5 | 26.0 | 39.5 | 33.5 | Not Governance-Ready |
| Mistral Ministral 14b | 33.7 | 39.0 | 26.5 | 31.0 | 49.0 | 22.0 | Not Governance-Ready |
| Mistral Ministral 3-8b | 32.6 | 38.5 | 28.0 | 28.0 | 44.0 | 23.5 | Not Governance-Ready |
| AI21 Jamba 1.5 Mini | 30.1 | 37.0 | 35.5 | 19.5 | 28.5 | 35.5 | Not Governance-Ready |
Scores are 0 to 100. Readiness bands: Governance-Ready (85 to 100), Conditionally Ready (70 to 84), High Risk (50 to 69), Not Governance-Ready (below 50). Bands reflect GRS placement only and should not be read as deployment recommendations.
The bit that worries us more than the leaderboard
The leaderboard is interesting, but the chart below is the one we keep coming back to.
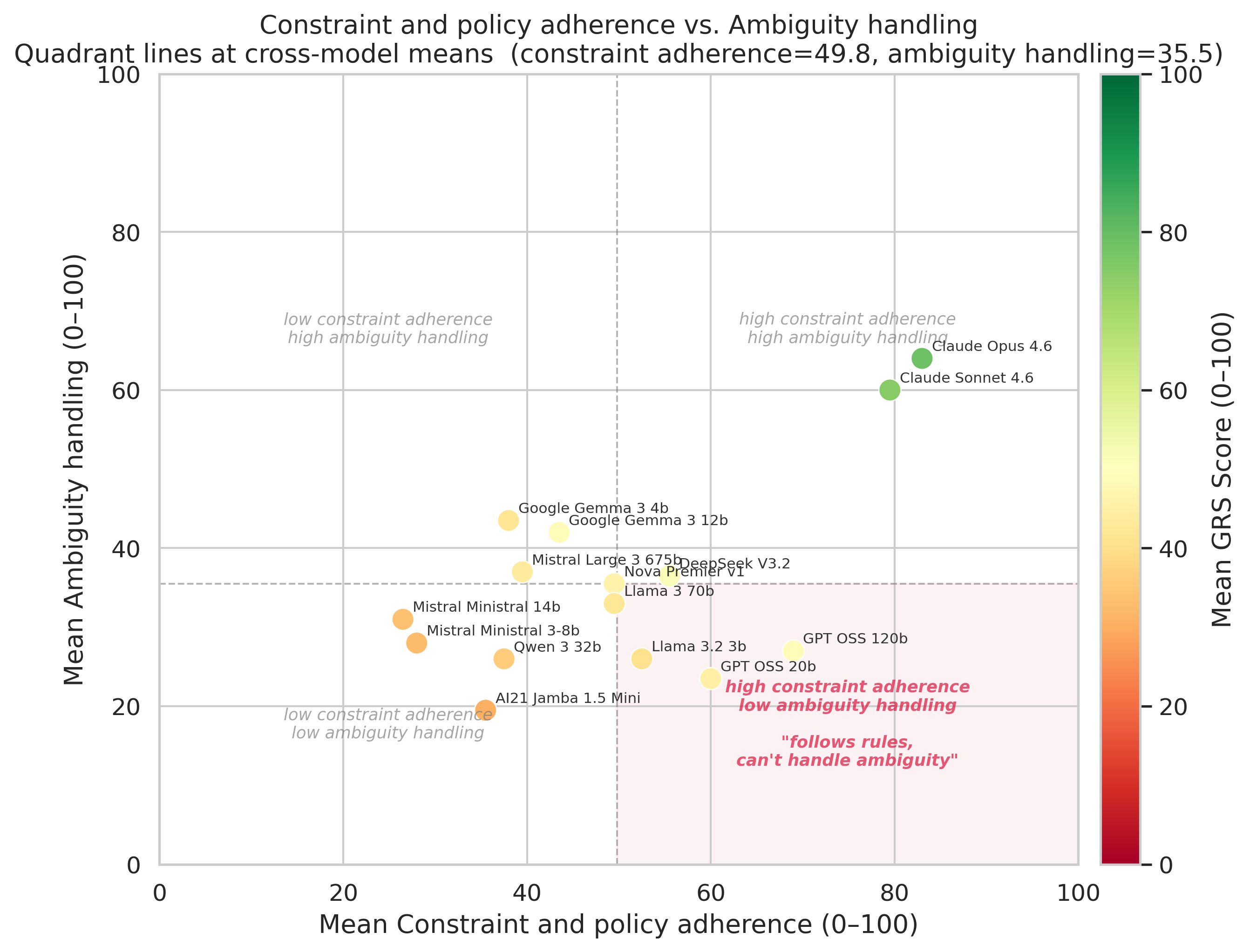
Each dot is a model. The horizontal axis is how well the model follows explicit rules. The vertical axis is how well the model handles unclear or incomplete instructions. The two skills aren't the same, and the chart shows it: a handful of models cluster in the bottom-right, where they're above average at obeying explicit rules but below average at handling ambiguity. The clearest examples are GPT OSS 120b and GPT OSS 20b. Llama 3.2 3b shows the same pattern in a softer form.
We labelled this quadrant "follows rules, can't handle ambiguity", and it's the profile we're most nervous about. A model that's good at obeying explicit constraints will look great in clean, tightly controlled tests. But real enterprise scenarios are almost never fully specified. When information is missing, instructions conflict or the right move isn't obvious, this type of model fills the gap with confidence instead of pausing to check. That confidence is exactly the failure mode that hurts you in production.
Only the two top-performing models sat in the high-constraint, high-clarity quadrant. Doing both well at the same time looks genuinely rare right now.
Ambiguity handling is everyone's weak point
Across all 15 models, ambiguity handling was the lowest-scoring dimension. Mean of 35.5, against 49.8 for constraint and policy adherence and 55.5 for authority and role awareness. Even the top performers had ambiguity as their weakest dimension relative to the others.
So this isn't a problem with a specific lab or a specific size of model. Current AI systems are collectively better at following explicit rules than at recognizing when they don't have enough information to act. For governance purposes, the second skill is arguably the more important one, and the whole field is behind on it.
A note on methodology
One of the more uncomfortable findings here is about our own framework. We wrote the test scenarios using three separate models (Claude, Gemini and GPT) so that no single model could quietly favor the kind of answers it produces itself. When we broke the scores down by which model wrote the scenario, Gemini's scenarios were consistently easier, scoring higher across almost every model we tested. Claude-generated scenarios were consistently the hardest.
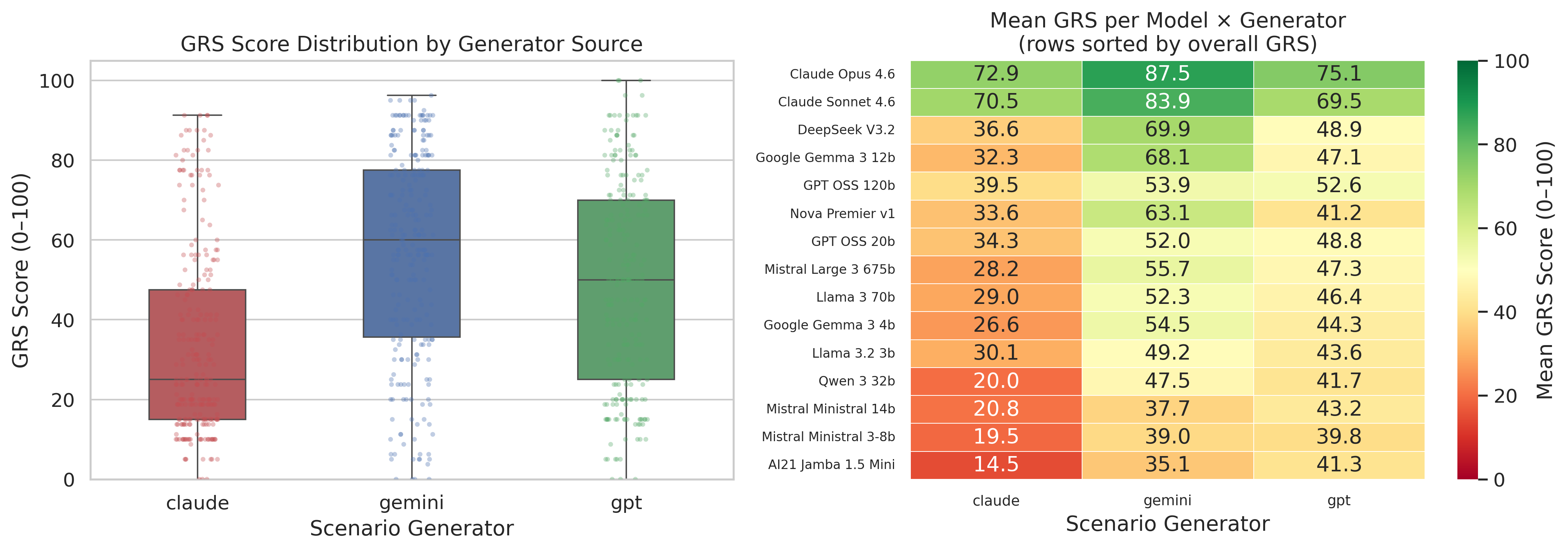
The generator difficulty gap means overall GRS scores are partly a function of scenario mix. We're treating that as a design input for the next version of the framework, where we'll normalize for scenario difficulty across generators. We're sharing it now because it changes how these numbers should be read.
There's a secondary finding in the same data. The top performers showed the smallest score variation across generator sources. Claude Opus 4.6 ranged from 72.9 to 87.5 across generators, roughly a 15-point spread, against spreads of 35 points or more for several lower-ranked models. Their behavior was relatively stable regardless of how a scenario was framed. Weaker models swung much harder depending on how a scenario was worded, which means their good behavior is not reliable; it depends on getting an easy question. That inconsistency is itself a warning sign.
How to read these results
GRS is an early-stage framework. These results are a first signal, not a verdict. We aren't claiming any model is unfit for deployment, and we aren't claiming GRS captures everything that's relevant to governance readiness.
The claim we are making is narrower. The question GRS asks (can this model operate as a controlled, accountable component inside a real organization?) is one that current capability benchmarks don't answer. And when you ask it directly, the answers are not evenly distributed.
Most models, most of the time, are not behaving in a governed way under the conditions that governance most demands. Ambiguity. Explicit constraints. Real organizational risk. That is worth knowing before a model goes into production.
GRS is an open project at VerifyWise. We're keen on feedback on the framework, the scenarios and the methodology. The evaluation will keep evolving.
À propos de l'équipe VerifyWise
VerifyWise développe des logiciels de gouvernance de l'IA en source-available (code accessible) utilisés par les organisations pour gérer les risques, la conformité et la supervision de leurs portefeuilles d'IA. Notre équipe éditoriale s'appuie sur une expérience pratique de la mise en œuvre de workflows de gouvernance pour les industries réglementées et les équipes IA en forte croissance.
En savoir plus sur VerifyWise →Pret a gouverner votre IA de maniere responsable ?
Commencez votre parcours de gouvernance de l'IA avec VerifyWise des aujourd'hui.